How to generate high-quality images and videos faster has long been a central objective in the generative modeling community. Early explorations mainly followed a numerical-analysis perspective: researchers aimed to design more efficient ODE solvers, such as DDIM1, DPM-Solver2, and iPNDM3, to approximate the target distribution with fewer sampling steps. At the same time, distillation is also an effective acceleration approach, although it usually requires additional training and higher resource cost.
In the era of large models such as FLUX and Wan, cache mechanisms have gradually become an acceleration direction that receives substantial attention in academia, mainly because they are training-free and plug-and-play. However, it is worth emphasizing that Cache in this context is almost unrelated to KV Cache in LLMs. Of course, quantization, pruning, and other directions are also developing. In the end, the goal remains the same: finding a better balance between efficiency and quality.
This post focuses on cache mechanisms. Based on my own research experience, I discuss two questions: how cache methods should be evaluated, and how this technical line has roughly evolved.
When opening a cache-related paper, the first metrics we usually see fall into two categories: visual quality and efficiency. For quality, common metrics include CLIP Score, ImageReward, and VBench. For Cache research, reconstruction metrics such as PSNR, SSIM, and LPIPS are also often considered. In contrast, the concept of “efficiency” is sometimes more implicit and ambiguous in many papers.
The most common efficiency metrics are latency and speedup. Latency is intuitive: it measures the time required to generate an image or a video, and is itself a reasonable metric. However, it strongly depends on the specific hardware and runtime workload. The same algorithm may show substantially different latency on different GPUs or under different concurrency settings. Therefore, if latency is used as the main selling point without sufficiently specifying the experimental environment and baseline setting, the comparison is not rigorous enough. In comparison, speedup can be even more problematic as a relative metric, because it is very sensitive to the baseline setting. Here, the baseline is usually the full-compute result under the original number of inference steps, namely the reference result used for computing reconstruction metrics.
Consider a simple arithmetic example. Suppose our goal is to generate an image of acceptable quality:
- Case A: the original number of inference steps is 50. With Cache, the model only fully computes 10 steps and skips 40 steps. The speedup is 50 / 10 = 5.0×.
- Case B: the original number of inference steps is 30. For models such as FLUX, 30 steps are usually already sufficient. With Cache, the model also fully computes only 10 steps and skips 20 steps. The speedup is 30 / 10 = 3.0×.
At first glance, Case A with 5.0× speedup seems much stronger than Case B with 3.0×, almost like a larger improvement. But after removing the effect of the baseline step count, we can see that both cases fully run the network only 10 times, and their actual inference latency is very close.
In ODE solver research, NFE, or Number of Function Evaluations, is widely used to measure how many times the denoising network is fully evaluated. It is a relatively objective and fair metric: it does not directly depend on hardware, and it is not easily affected by the original step setting. For Step-Level Cache methods, NFE is very suitable for evaluation, because what these methods truly reduce is the number of full network forward passes.
After clarifying the evaluation metrics, we can briefly review the development of Cache techniques. The generation process of diffusion models relies on iterative denoising, and redundancy exists at different granularities. Early explorations mainly focused on redundancy inside the model architecture. DeepCache4 and Delta-DiT5, which targets DiT architectures, both observed a similar phenomenon: deep semantic features change slowly between adjacent timesteps, while shallow features change more quickly. Based on this observation, one can selectively skip the computation of some deep blocks and directly reuse the feature maps from the previous timestep, making the network “thinner” within a single inference step.
As DiT architectures became more widely used, researchers further moved to a finer Token-Level granularity, with representative methods including ToCa6 and DuCa7. These methods identify redundant tokens and reduce computation in modules such as Attention through pruning or merging. It is worth noting that both Layer-Level and Token-Level methods essentially reduce FLOPs within a single network forward pass, while the total number of network steps does not change. Therefore, NFE is not the best metric for evaluating these methods.
From late 2024 to 2025, Step-Level Cache gradually became a major direction in Cache research, with representative methods such as TeaCache8, MagCache9, LeMiCa10, and MeanCache11. Unlike Layer-Level or Token-Level methods, these methods directly decide at the timestep level whether to execute the full network. Therefore, their engineering implementation is simpler, and they also affect the actual NFE more directly. Step-Level Cache follows a simple logic: if the overall output of the model changes only slightly between adjacent timesteps, then we can directly skip all DiT Blocks. This indeed reduces the actual NFE, shortens the inference process, and lowers latency accordingly. More importantly, the core question at this stage shifts from “what to cache” to “when to cache.”
Early Cache attempts often used a simple Uniform Strategy, mechanically computing once every $K$ steps, with the focus still on cache objects such as tokens, layers, or blocks. Some papers use historical information for prediction to mitigate the error caused by direct reuse. The key of Step-Level Cache, however, is to introduce a more reasonable Heuristic Strategy, dynamically deciding whether to skip the current step based on a threshold. This transition from Static Uniform to Dynamic Heuristic makes the allocation of NFE better match the non-uniform nature of the generation process, and usually has advantages in engineering implementation and stability.
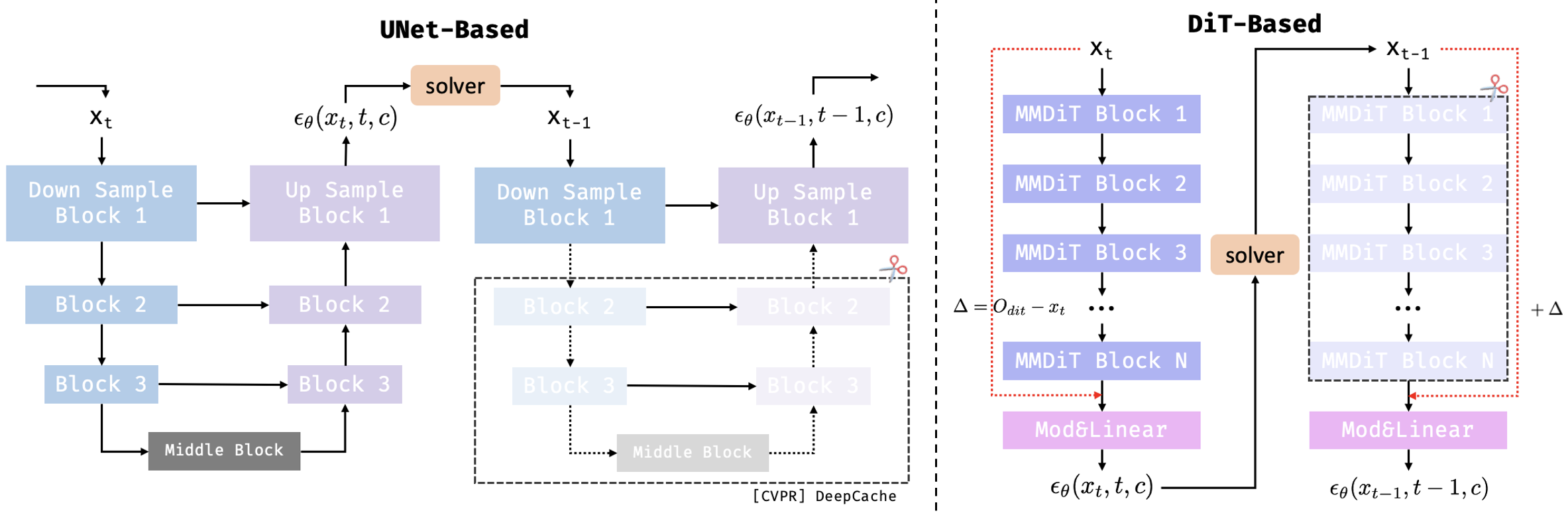
Figure 1. Differences between cache strategies in two common diffusion model architectures. UNet architectures usually cache the Feature itself, while DiT architectures more often cache the change/residual.
Of course, heuristic strategies are not perfect. They are essentially greedy and short-sighted: whether to cache the current step is usually determined only by local signals, but the caching error will continue to propagate and accumulate in later timesteps. This means that the globally optimal strategy may not be recoverable from local threshold decisions. When analyzing error accumulation, many papers intentionally or unintentionally blur this point: they do not sufficiently consider how errors propagate and accumulate under consecutive caching. Of course, we also acknowledge that accurately characterizing the full error accumulation process is itself difficult.
Another issue is that threshold-based decisions introduce clear uncertainty. The mapping between the threshold and the actual NFE is usually not transparent: if the threshold is set to 0.24 or 0.36, how many NFEs will it eventually correspond to? Under different prompts, will the same threshold lead to substantial fluctuations in computation cost? These questions are important for engineering deployment.
LeMiCa10 and DPCache12 have started to consider constructing a global caching strategy, and this objective is reasonable. Their limitation is that the error/value used for planning is not the true error produced by consecutive cache on the current test instance, but a forecast/proxy obtained through offline calibration. Overall, it is reasonable to define the goal of a Cache task as “under a fixed computation budget, making the generated result have a smaller error relative to the full-compute reference result,” which means paying more attention to reconstruction metrics. From an application perspective, adding final quality metrics such as ImageReward and HPS to the evaluation is naturally more rigorous.
The narrative that Cache strategies should be instance-aware is intuitively reasonable. However, in practice, the difficulty lies in how to define an instance. This is especially true for large-scale foundation models, where the same prompt can correspond to multiple reasonable generated results, and the similarity between different concept combinations is difficult to define precisely. It is not difficult for a model such as FLUX to generate images containing concept combinations, but it is difficult for humans to establish a clear and operational distance metric for these combinations.
This leads to a direct question: do 1000 different generated results require 1000 different caching strategies? If not, how can we justify that two different generated results should share the same caching strategy? This question suggests that when designing a method, it is better to first focus on a clearly defined and verifiable problem, and then analyze whether the method exhibits properties such as instance awareness that align with intuition.
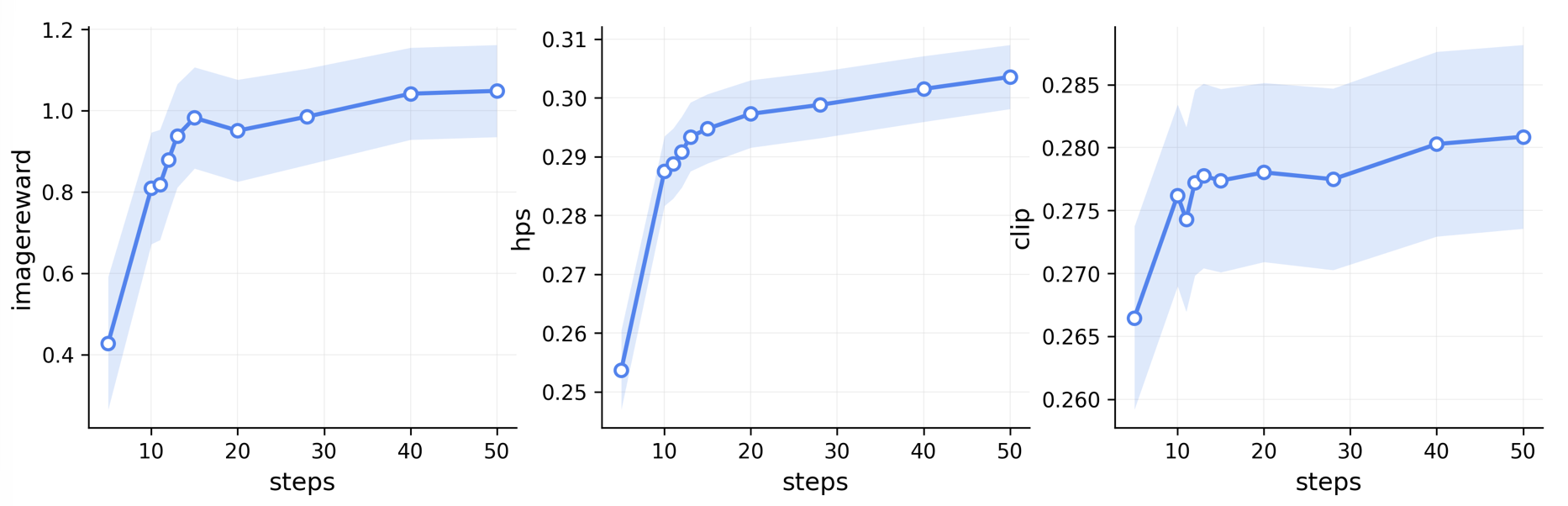
Figure 2. Analysis of the effect of NFE/steps on final image quality. The test set contains 200 prompts from DrawBench, and the tested model is FLUX.1-dev.
The results above seem to suggest that the application-level benefit of Cache methods should be evaluated carefully. For base models such as FLUX, the generation quality is already relatively stable under a computation budget of around a dozen NFEs; this range also roughly corresponds to the actual NFE reported by many current Cache papers. Therefore, if we only look at final quality metrics such as ImageReward and HPS, whether Cache is used may not always lead to a substantial difference.
This is why I emphasized reconstruction metrics earlier. If the goal is to study the Cache mechanism itself, then a more reasonable comparison is to examine, under a fixed computation budget, the error relative to the full-compute reference result, rather than only checking whether the final image quality remains acceptable.
Song, Jiaming, Chenlin Meng, and Stefano Ermon. “Denoising diffusion implicit models.” arXiv preprint arXiv:2010.02502. 2020. ↩︎
Lu, Cheng, et al. “Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.” Advances in Neural Information Processing Systems 35. 2022: 5775-5787. ↩︎
Zhou, Zhenyu, et al. “Fast ode-based sampling for diffusion models in around 5 steps.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024. ↩︎
Ma, Xinyin, Gongfan Fang, and Xinchao Wang. “Deepcache: Accelerating diffusion models for free.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024. ↩︎
Chen, Pengtao, et al. “$\Delta$-DiT: A Training-Free Acceleration Method Tailored for Diffusion Transformers.” arXiv preprint arXiv:2406.01125. 2024. ↩︎
Zou, Chang, et al. “Accelerating diffusion transformers with token-wise feature caching.” arXiv preprint arXiv:2410.05317. 2024. ↩︎
Zou, Chang, et al. “Accelerating diffusion transformers with dual feature caching.” arXiv preprint arXiv:2412.18911. 2024. ↩︎
Liu, Feng, et al. “Timestep Embedding Tells: It’s Time to Cache for Video Diffusion Model.” Proceedings of the Computer Vision and Pattern Recognition Conference. 2025. ↩︎
Ma, Zehong, et al. “Magcache: Fast video generation with magnitude-aware cache.” Advances in Neural Information Processing Systems 38 (2026): 34348-34380. ↩︎
Gao, Huanlin, et al. “Lemica: Lexicographic minimax path caching for efficient diffusion-based video generation.” arXiv preprint arXiv:2511.00090 (2025). ↩︎ ↩︎
Gao, Huanlin, et al. “MeanCache: From Instantaneous to Average Velocity for Accelerating Flow Matching Inference.” arXiv preprint arXiv:2601.19961 (2026). ↩︎
Cui, Bowen, et al. “Denoising as Path Planning: Training-Free Acceleration of Diffusion Models with DPCache.” arXiv preprint arXiv:2602.22654 (2026). ↩︎