Introduction
当今 AI 相关研究往往都不可能是在本地完成的。无论是微调 LLM 还是训练 Diffusion Model,我们都需要连接远程服务器,甚至使用更加复杂的 HPC (High Performance Computing) 集群。
如果只是单台服务器,体验类似一台没有 GUI 的大号电脑;但到了 Slurm 集群,逻辑就完全不同了。许多刚入门的 Researcher 容易在这里迷失,把时间浪费在配置环境和排队报错上。
The Core Thesis: 构建高效的科研基建(Research Infra),核心不在于掌握多少 Linux 命令,而在于建立一套可复现易用的标准工作流,花更多的时间打磨Research本身。
本文将从零开始,梳理一套经过实战检验的服务器生存指南。
1. 理解 Slurm 架构
Slurm 集群的核心特点是 “资源与执行分离”。我们可以用个人电脑的组件来类比整个集群:
- 登录节点 (Login Node) \(\approx\) 显示器与键盘:你唯一能直接操作的地方,用于写代码、配环境。千万不要在这里跑重计算任务。
- 存储节点 (Storage) \(\approx\) 硬盘:所有节点共享的文件系统,存放你的 Code, Data, Model Weight。
- 计算节点 (Compute Node) \(\approx\) 显卡 (GPU):真正干活的地方,通常无法直接联网。
- 调度器 (Scheduler) \(\approx\) 操作系统内核:负责分配资源,你必须向它“申请”才能使用硬件。
2. Access: 登录与鉴权
在终端通过SSH连接通常是第一步。推荐配置 SSH 免密登录,这不仅是为了省去输密码的时间,更是为了 VS Code Remote 等工具的稳定性。 在本地终端执行:
# 1. 本地生成公钥私钥 (默认回车即可)
ssh-keygen -t rsa -b 4096
# 2. 将公钥复制到远程服务器 (自动追加到 ~/.ssh/authorized_keys) 当然也可以手动复制
ssh-copy-id user@your-server-ip
3. Conda 环境管理
在 /data 或 /share 等大容量存储盘下安装 Miniconda 是标准方式,官方提供了简明扼要的指南。
注意:部分 HPC 集群提供了module辅助相关软件的安装,例如运行 module load miniconda 或 module load cuda,这方面通常会有配套使用文档。
为了兼顾易用性和复用性,我建议按研究方向而不是按项目来维护环境(例如维护一个通用的 ImageGen 环境),避免磁盘空间爆炸。
# 创建一个通用环境
conda create -n qwenImage python=3.12
conda activate qwenImage
# 核心包一次性装好,保证版本兼容
pip install torch==2.5.1 torchvision deepspeed diffusers \
numpy==1.26.4 opencv-python-headless bitsandbytes>=0.46.0 \
einops gradio nvitop peft>=0.17.0 safetensors \
wandb matplotlib sentencepiece modelscope \
-i https://pypi.tuna.tsinghua.edu.cn/simple
4. 模型权重下载
在集群登录节点上下载模型,推荐使用官方的 CLI 工具,例如huggingface-cli/modelscope。
高效下载技巧
- 设置镜像:国内环境必备
HF_ENDPOINT。 - 修改缓存路径:
HF_HOME默认在~/.cache,很容易撑爆 Home 目录配额。建议在.bashrc中修改到/data盘。当然更推荐直接指定local-dir。 - 文件过滤:使用
--exclude排除冗余文件(如同时存在的.bin和.safetensors)。
# 建议写入 ~/.bashrc
export HF_HOME="/data/leimingkun/.cache/huggingface"
# 下载命令示例
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download meituan-longcat/LongCat-Image \
--local-dir LongCat-Image/ \
--resume-download \
--exclude "*.bin" "*.pth" # 只下载 safetensors,节省空间与时间
5. Slurm 任务提交
使用 sinfo 看集群资源全貌:
[leimingkun@login01 ~]$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
A800 up infinite 10 mix a800-[001-010]
对于使用来说最需要关注的是节点是否空闲,也就是 STATE 状态。但 mix 并不一定意味着有充足的 GPU,因为可能只是 CPU 没有占满而 GPU 已满。一个简单的办法是 scontrol show node a800-001,这样能清晰看到 GPU 是否空闲以及剩余资源。
使用squeue可以查看具体任务信息,重点关注JOB_ID以及ST信息。
[leimingkun@login01 ~]$ squeue -u leimingkun
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
8726832 a800 interact leimingk R 6-02:24:42 1 a800-003
在 Slurm 上,我们有三种方式索要资源:salloc, srun (交互), sbatch (批处理)。
我个人不太建议在科研长任务里用 srun。它容易因为网络波动导致 session 断开。sbatch 脚本即代码,它留下了可追溯的实验记录。
供参考 sbatch 模板 (run_exp.sh)
#!/bin/bash
#SBATCH --partition=a800 # 分区名称
#SBATCH --gres=gpu:1 # 申请 1 张卡
#SBATCH --cpus-per-task=16 # 配套 CPU 核数
#SBATCH --mem=64G # 内存
#SBATCH --job-name=dit_train_v1 # 任务名
#SBATCH --output=logs/%x_%j.log # 日志归档
#SBATCH --time=3-00:00:00 # 最长运行时间 (3天)
# 1. 加载环境
source ~/miniconda3/etc/profile.d/conda.sh
conda activate qwenImage
# 2. 运行任务
python train_diffusion.py --config config/train.yaml
提交任务只需:sbatch run_exp.sh。
6. The Debugging Protocol
这是新手最头疼的环节:“代码怎么调试?”
最优雅的方案是 Interactive Debugging (salloc + tmux)。
在开始 debug 前,务必开启 tmux,防止 SSH 断开导致关键log丢失。
tmux new -s debug_session:新建会话Ctrl+B松手后按D:暂时离开 (Detach)tmux a -t debug_session:回来 (Attach)
- 申请资源:使用
salloc申请一个计算节点。
# 像 login 节点一样进入计算节点终端
salloc -p a800 --gres=gpu:1 --cpus-per-task=16 --mem=64G
- 定位节点:申请成功后,终端 prompt 通常会变(如变为
leimingkun@a800-002)。如果没有变,可以使用ssh连接分到的节点。 - 开始调试:现在你拥有了 GPU,可以使用
python -m pdb train.py进行断点调试。 - 释放资源:调试结束使用
scancel job_id释放资源,否则会持续计费或占用公共资源。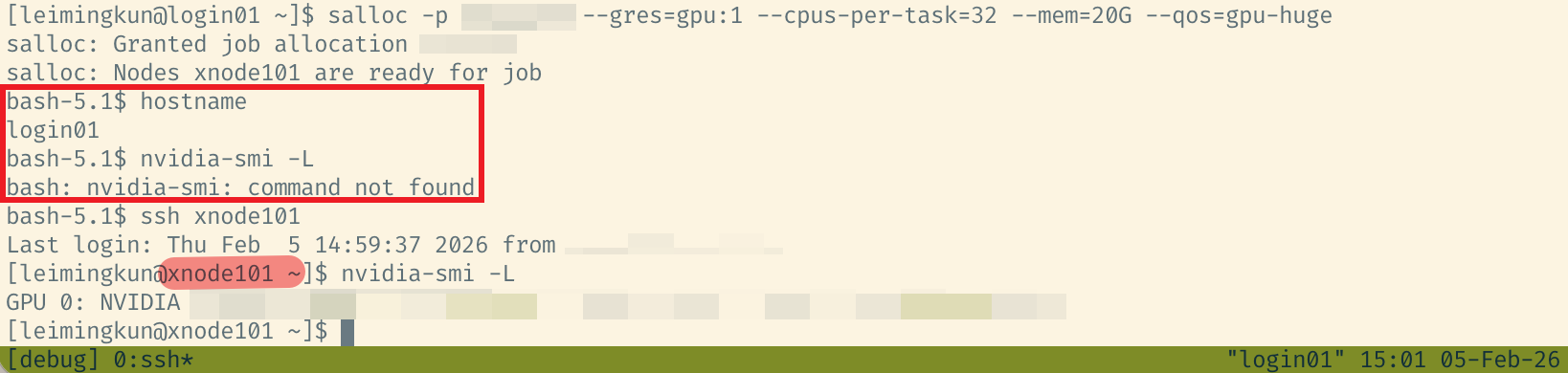
Figure 1. 使用salloc并连接计算节点示意
Summary
掌握了 SSH Config (连接) -> Conda (环境) -> HF CLI (数据) -> Slurm (算力) 这条链路,你就拥有了坚实的 Research Infra。
在下一篇文章中,我们将探讨 Observability(可观测性),详细讲解如何配置 WandB 和 TensorBoard 来监控这些在远端黑盒中运行的实验。
附:VSCode Remote-SSH
不同集群策略差异很大:
- 有的集群提供开发机或允许直接连登录节点,这时按常规 Remote-SSH 使用即可。
- 有的集群禁止 VSCode 连接登录节点,只允许连接计算节点,这时就需要写
~/.ssh/config,通常要配ProxyJump等跳板配置。 当遇到不允许直接连接计算节点,甚至登录节点也需要通过堡垒机跳转的情况时。此时修改本地~/.ssh/config是最佳实践:
# ~/.ssh/config 示例
# 1. 登录节点 (跳板)
Host slurm_login
HostName 10.1.10.1
User leimingkun
Port 22
# 2. 计算节点 (通过 Login 节点跳转)
# 这样 VS Code 可以直接连上计算节点进行 Debug
Host compute_node
HostName a800-001
User leimingkun
ProxyJump slurm_login