如何更快地生成高质量图像/视频,一直是生成模型社区的核心追求。早期的探索主要集中在数值分析视角:研究者希望构建更高效的 ODE Solver,例如 DDIM1、DPM-Solver2 和 iPNDM3,从数学上用更少的采样步数逼近目标分布。与此同时,蒸馏(Distillation)也是一种立竿见影的加速手段,只是通常需要额外训练,资源开销也更大。
到了 FLUX、Wan 这类大模型时代,缓存(Cache)机制凭借免训练(Training-Free)和即插即用(Plug-and-Play)的特点,逐渐成为学术界关注的一条加速路线。但是值得强调的是,这里的 Cache 与 LLM 中的 KV Cache 几乎没有任何联系。当然,量化、剪枝等路线也在发展。归根结底,大家追求的目标仍然是同一个:在效率和质量之间找到更好的平衡。
本文聚焦缓存机制,结合自己的研究经历,讨论两个问题:缓存方法应该如何评估,以及这条技术路线大致是如何演进的。
打开一篇缓存相关论文,最先看到的通常是两类指标:质量(Visual Quality)和效率(Efficiency)。质量方面,常见指标包括 CLIP Score、ImageReward、VBench 等;对于 Cache 研究,还经常会额外关注重建指标,例如 PSNR、SSIM 和 LPIPS。相比之下,“效率”这个概念在很多论文里反而有些隐性模糊。
最常见的效率指标是延迟(Latency)和加速比(Speedup)。延迟很直观,指生成一张图片或一段视频所需的时间,本身是合理指标。但它强依赖具体硬件和运行负载。同一个算法在不同 GPU、不同并发环境下的延迟可能差异明显。因此,如果只用延迟作为主要卖点,而不充分说明实验环境和基线设置,就不够严谨。相比之下,加速比这个相对概念的问题可能更大,因为它非常容易受到基线设置的影响。这里的基线通常是原始推理步数(num inference steps)下的 full-compute 结果,也就是用于计算重建指标的参考结果。
来看一个简单的算术题。假设我们的目标是生成一张质量达标的图:
- Case A:原始 inference steps 为 50 步。使用 Cache 后,实际只完整计算 10 步,跳过 40 步。此时 Speedup = 50 / 10 = 5.0×。
- Case B:原始 inference steps 为 30 步。对于 FLUX 这类模型来说,30 步通常已经足够。使用 Cache 后,同样只完整计算 10 步,跳过 20 步。此时 Speedup = 30 / 10 = 3.0×。
乍一看,Case A 的 5.0× 似乎比 Case B 的 3.0× 强很多,甚至像是一个更大的突破。但剥离掉基线步数的影响后会发现:两者都只完整运行了 10 次网络,实际推理延迟非常接近。
在 ODE Solver 相关研究中,NFE(Number of Function Evaluations)被广泛用来衡量 Denoising Network 实际完整运行的次数。它是一个相对客观公正的指标:不直接依赖硬件,也不容易被原始步数设置影响。对于 Step-Level Cache 这类方法来说,NFE 用于评测非常合适,因为这类方法真正减少的就是网络完整 forward 的次数。
厘清评估指标后,我们可以简单回顾一下 Cache 技术的发展脉络。扩散模型的生成过程依赖循环去噪,而冗余其实存在于不同粒度之中。早期探索主要关注模型架构内部的冗余。DeepCache4 以及面向 DiT 架构的 Delta-DiT5 都捕捉到了类似现象:深层语义特征在相邻时间步之间变化较慢,而浅层特征变化更快。基于这个观察,我们可以选择性跳过部分深层 Block 的计算,直接复用上一时刻的 Feature Map,从而让网络在单次推理中变得“更薄”。
随着 DiT 架构的普及,研究者进一步把目光放到更细粒度的 Token-Level,代表方法包括 ToCa6 和 DuCa7。这类方法通过识别冗余 Token,并进行剪枝(Pruning)或合并(Merging),从而减少 Attention 等模块的计算量。需要注意的是,无论是 Layer-Level 还是 Token-Level,本质上都是在单次网络推理内部减少 FLOPs,网络运行的总步数并没有改变。因此,NFE 并不是衡量这类方法的最佳指标。
到了 2024 年末至 2025 年,Step-Level Cache 逐渐成为 Cache 研究中的主要方向,例如 TeaCache8、MagCache9、LeMiCa10 和 MeanCache11。与 Layer-Level 或 Token-Level 方法不同,这类方法直接在时间步层面决定是否执行完整网络,因此工程实现更简单,也更直接影响实际 NFE。 Step-Level Cache 的逻辑十分简洁:如果模型相邻时间步的整体输出变化足够小,那就直接跳过全部 DiT Blocks。这种做法确实减少了实际 NFE,让推理过程真正缩短,延迟也随之降低。更重要的是,这一阶段的核心问题从“缓存什么”(What to cache)转向了“什么时候缓存”(When to cache)。
早期 Cache 尝试往往采用朴素的 Uniform Strategy,也就是机械地每隔 $K$ 步计算一次,重点仍然在 Token、Layer 或 Block 这些缓存对象上,部分论文通过利用历史信息进行预测的方式来缓解直接复用带来的误差。而 Step-Level Cache 的关键在于引入更合理的 Heuristic Strategy,通过阈值(threshold)动态决定是否跳过当前步。这种从 Static Uniform 到 Dynamic Heuristic 的转变,让 NFE 的分配更符合生成过程本身的非均匀性,在工程实现和效果稳定性上通常也更有优势。
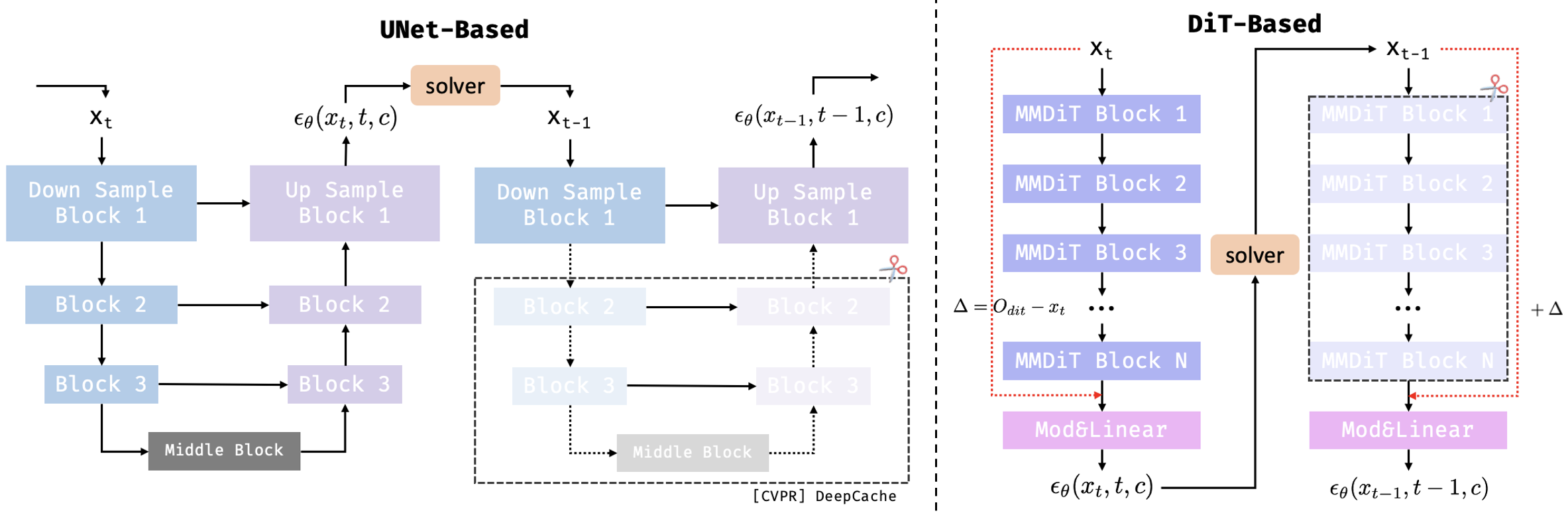
Figure 1. 两种常见扩散模型架构的缓存方式差异。UNet 架构通常缓存 Feature 本身,而 DiT 架构更常缓存变化量/残差。
当然,启发式策略并不完美。它本质上是贪心且短视的:当前步是否缓存通常只由局部信号决定,但缓存误差会继续向后传播,并在后续时间步中累积。这意味着全局最优策略未必能由局部阈值判定得到。大部分论文在分析误差累积时,有意或无意地模糊了这一点:它们没有充分考虑连续缓存场景下误差如何传播和累积。当然,我们也承认,精确刻画完整的误差累积过程本身是很困难的。
另一方面,基于阈值的判定会带来明显的不确定性。阈值和实际 NFE 之间通常不是透明映射:把阈值设为 0.24 或 0.36,最终会对应多少 NFE?同一个阈值在不同 prompt 下是否会导致计算量显著波动?这些问题在工程部署中都非常关键。
LeMiCa10 以及 DPCache12 已经开始考虑构建全局缓存策略,这一目标是合理的。但它们的局限在于,规划所依赖的 error/value 并不是当前 test instance 在连续 cache 后产生的真实误差,而是通过离线 calibration 得到的 forecast/proxy。 总而言之,将 Cache 任务的目标定义为“在固定计算量下,使生成结果相对于 full-compute 参考结果具有更小误差”是合适的,也就是更关注重建指标。从应用角度来看,在评估中加入 ImageReward 以及 HPS 等最终质量指标自然会更加严谨。
Cache 策略具有 instance-aware 的叙事逻辑,这一点在直觉上是合理的。但在实际推进中,困难在于如何定义 instance。尤其是在 large-scale foundation models 中,同一个 prompt 可以对应多种合理生成结果,不同概念组合之间的相似性也难以精确定义。让 FLUX 这类模型生成概念组合并不困难,但人类很难为这些组合建立一个清晰、可操作的距离度量。
因此,一个直接的问题是:是否 1000 张不同生成结果就需要 1000 个不同缓存策略?如果不是,我们又如何说明其中两个生成结果共享同一缓存策略是合理的?这个问题说明,在设计方法时,最好先聚焦于一个可明确定义和验证的问题,再分析方法是否呈现出 instance-aware 等符合直觉的性质。
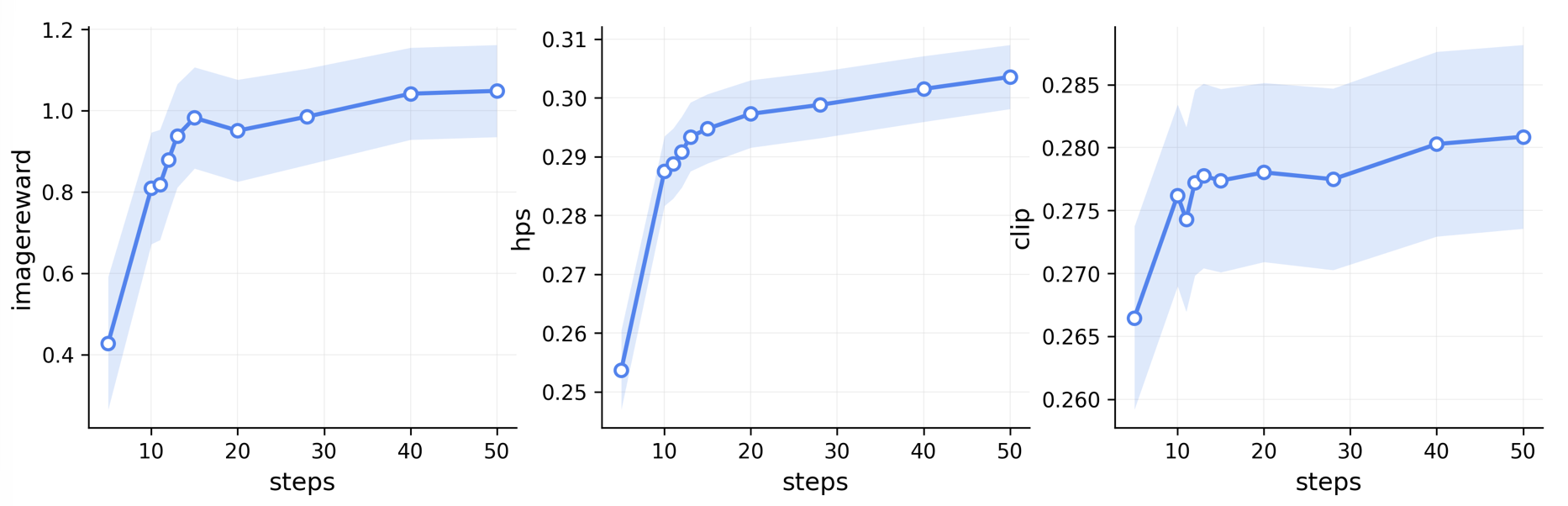
Figure 2. NFE/steps 对于最终图像质量的影响分析,测试数据为 DrawBench 的 200 条文本,测试模型为 FLUX.1-dev。
上图的结果似乎表明,Cache 方法在应用层面的收益需要谨慎评估。对于 FLUX 这类基座模型,在十几步 NFE 的计算预算下,生成质量本身已经较为稳定;而这一区间也大致对应当前许多 Cache 论文报告的实际 NFE。因此,单从 ImageReward、HPS 等最终质量指标来看,是否使用 Cache 可能并不总是产生显著差异。
这也是我前面强调重建指标的原因:如果目标是研究 Cache 机制本身,那么更合理的比较方式是在固定计算量下,考察其相对于 full-compute 参考结果的误差,而不是只看最终图像质量是否仍然可接受。
Song, Jiaming, Chenlin Meng, and Stefano Ermon. “Denoising diffusion implicit models.” arXiv preprint arXiv:2010.02502. 2020. ↩︎
Lu, Cheng, et al. “Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.” Advances in Neural Information Processing Systems 35. 2022: 5775-5787. ↩︎
Zhou, Zhenyu, et al. “Fast ode-based sampling for diffusion models in around 5 steps.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024. ↩︎
Ma, Xinyin, Gongfan Fang, and Xinchao Wang. “Deepcache: Accelerating diffusion models for free.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024. ↩︎
Chen, Pengtao, et al. “$\Delta$-DiT: A Training-Free Acceleration Method Tailored for Diffusion Transformers.” arXiv preprint arXiv:2406.01125. 2024. ↩︎
Zou, Chang, et al. “Accelerating diffusion transformers with token-wise feature caching.” arXiv preprint arXiv:2410.05317. 2024. ↩︎
Zou, Chang, et al. “Accelerating diffusion transformers with dual feature caching.” arXiv preprint arXiv:2412.18911. 2024. ↩︎
Liu, Feng, et al. “Timestep Embedding Tells: It’s Time to Cache for Video Diffusion Model.” Proceedings of the Computer Vision and Pattern Recognition Conference. 2025. ↩︎
Ma, Zehong, et al. “Magcache: Fast video generation with magnitude-aware cache.” Advances in Neural Information Processing Systems 38 (2026): 34348-34380. ↩︎
Gao, Huanlin, et al. “Lemica: Lexicographic minimax path caching for efficient diffusion-based video generation.” arXiv preprint arXiv:2511.00090 (2025). ↩︎ ↩︎
Gao, Huanlin, et al. “MeanCache: From Instantaneous to Average Velocity for Accelerating Flow Matching Inference.” arXiv preprint arXiv:2601.19961 (2026). ↩︎
Cui, Bowen, et al. “Denoising as Path Planning: Training-Free Acceleration of Diffusion Models with DPCache.” arXiv preprint arXiv:2602.22654 (2026). ↩︎