如何更快地生成出高质量的图像/视频一直是社区的核心追求。回顾早期的探索,研究者们主要致力于从数值分析的视角构建高效的 ODE Solver(如我们熟知的 DDIM(Song et al.), DPM-Solver(Lu et al.), iPNDM(Zhou et al.)),试图在数学上用更少的步数逼近真实分布。与此同时,蒸馏(Distillation) 也是立竿见影的手段。而在 FLUX/Wan 等大模型时代,缓存(Cache)机制凭借其免训练(Training-Free)和即插即用(Plug-and-Play)的特性,迅速占据了一席之地。 当然,量化、分布式推理等手段也在百花齐放。但万变不离其宗,我们追求的终极目标始终是 效率与质量的平衡。
本文将聚焦于缓存(Cache)机制展开深度讨论。但我并不打算简单地罗列论文综述,而是想分享在进行相关研究时,对于这一领域评估标准与演进脉络的复盘与反思。 当我们打开一篇缓存相关的论文,最先映入眼帘的往往是两类指标:质量(Visual Quality)与效率(Efficiency)。 关于质量,我们有 CLIP Score, ImageReward, VBench 等常用指标,Cache研究还会额外关注重建指标(PSNR/LPIPS)。然而,关于“效率”的定义,社区中却存在着某种“隐性的模糊”。 最常见的指标是 延迟(Latency)和加速比(Speedup)。这两个指标固然直观,但它们本质上是相对概念:
- 硬件依赖性: 同样的算法,在H100和A100上,甚至在不同的负载和显存状态下,延迟差异巨大。
- 基线的不透明: 加速比是一个极易被“基线设定(即num inference steps的实际设置,通常我们可以简单认为是Ground Truth)”操控的相对指标。
让我们来看一个简单的算术题。假设我们的目标是生成一张质量达标的图:
- Case A: inference steps使用了50步。通过Cache,实际只计算了10步(跳过了40步)。 Speedup=50/10=5.0×
- Case B: inference steps只用了30步(对于FLUX而言是足够的)。通过Cache同样只计算了10步(跳过了20 步)。 Speedup=30/10=3.0×
乍一看,Case A(5.0x)似乎比Case B(3.0x)厉害得多,是一项“重大突破”。但当我们剥离掉基线设定的干扰,回归到计算本质时,我们会发现:两者都需要 10 次网络推理,实际的推理延迟是几乎一样的。并且实际上二者得图像质量并不会有实质性的差异。 因此,我认为衡量Step-Level Cache最诚实、最硬核的指标,应该是NFE(Number of Function Evaluations),即Denoising Network实际完整运行的次数。这是一个绝对数值,它剥离了硬件和基线的干扰,直指计算成本的核心,同时也被ODE Solver相关研究广泛运用。
Figure 1.
在厘清了评估指标之后,我们不妨简单回顾下Cache技术的发展脉络。如果我们将生成过程视为特征在时间轴上的流动与演变,那么冗余其实广泛存在于不同的粒度之中。早期的探索主要集中在模型架构内部的冗余。作为缓存机制的先行者,DeepCache(Ma et al.) 与针对 DiT 架构的 Delta-DiT(Chen et al.) 敏锐地捕捉到了特征演化的规律:深层语义特征在相邻时间步间的变化极其缓慢,而浅层特征变化较快。基于此,我们可以选择性地跳过某些深层 Block 的计算,直接复用上一时刻的 Feature Map,从而让网络变得“更薄”。而随着 DiT 架构的普及,研究者的目光进一步聚焦到了更细粒度的 Token-Level,以 ToCa(Zou et al.) 和 DuCa(Zou et al.) 为代表。通过剪枝(Pruning)或合并(Merging)判定的冗余 Token,可以显著减少 Attention 的计算量。值得注意的是,无论是 Layer-Level 还是 Token-Level,本质上都是在单次推理内部做减法(减少 FLOPs),网络运行的总步数并没有改变,自然NFE在这里并不是一个适用的衡量指标。
而到了2024年末至2025年爆发的Step-Level研究(如TeaCache, MagCache, LeMiCa, MeanCache),则代表了缓存机制向宏观粒度的跨越。从某种意义上来说,这一波爆发很大程度上是被视频生成逼出来的,这类方法的逻辑更加激进且直观:如果相邻时间步的整体输出变化足够小,我们为何不直接跳过整个网络的Forward Pass?这种“步数级冗余”的挖掘,直接将推理过程变得“更短”了。而这一阶段最深刻的进化,在于决策逻辑从“Cache什么”(What to cache)转向了“何时Cache”(When to cache)。 早期的Cache尝试往往采用朴素的Uniform Strategy(均匀策略),机械地“每隔K步算一次”,重点关注What to cache(Token/Layer/Block)。但这种静态策略忽略了 Diffusion 模型的生成过程特点是非线性的,生成初期的结构构建与末期的纹理细化。均匀跳过往往会导致关键步的质量崩塌或平滑步的算力浪费。 因此,Step-Level Cache的核心贡献在于转向了制定合理高效的Heuristic Strategy(启发式策略),通过阈值(threshhold)调整Cache策略。这种从Static Uniform到Dynamic Heuristic的范式转移,让NFE的分配真正符合了生成的内在规律特点,不论是工程实现还是最终效果稳定性上都更加优秀。 在这种语境下,网络实际完整运行的次数应当是衡量这一类方法效率的更合理的标准。
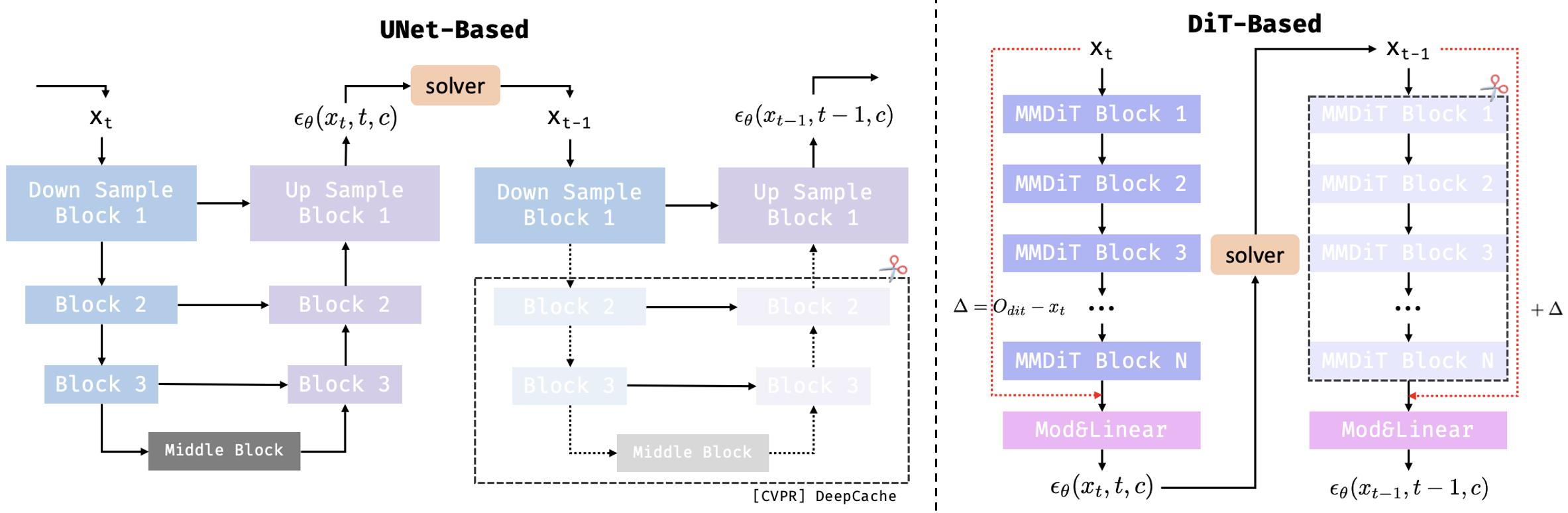
Figure 2. 两种常见扩散模型架构的缓存方式差异。 UNet架构缓存的是Feature本身,而DiT架构缓存的是变化量/残差(Chen et al.)。DiT架构为何一定会存在这样的差异我们在后续会进一步讨论。
当然启发式策略不是完美的,该策略是贪心且短视的,一方面在生成过程中缓存所带来的误差是会向下传递不断累积甚至放大的,意思其实是有很大概率会存在更优解;另一方面,这种基于阈值的判定带来了极大的不确定性。阈值与实际 NFE 之间是一个不可控的黑盒映射,我们很难直观地知道,将阈值设为 0.24或者0.36 到底会对应多少 NFE?对于不同的 Prompt,同样的阈值是否会导致计算量忽高忽低?这种不可控性,恰恰是工程部署中最大的痛点。更深一步从理想化的角度来思考,我们可能更需要探索出Cache的上限在哪?给定预算(固定NFE)Cache策略的上限究竟在哪?是否能够通过其他的手段进一步提升缓存机制的上限(例如当前DiT架构下的$\Delta$缓存方式是否就是最优解)。
持续更新中…
References
[1] Chen, Pengtao, et al. “$\Delta $-DiT: A Training-Free Acceleration Method Tailored for Diffusion Transformers.” arXiv preprint arXiv:2406.01125 (2024).
[2] Ma, Xinyin, Gongfan Fang, and Xinchao Wang. “Deepcache: Accelerating diffusion models for free.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2024.
[3] Song, Jiaming, Chenlin Meng, and Stefano Ermon. “Denoising diffusion implicit models.” arXiv preprint arXiv:2010.02502 (2020).
[4] Lu, Cheng, et al. “Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.” Advances in neural information processing systems 35 (2022): 5775-5787.
[5] Zhou, Zhenyu, et al. “Fast ode-based sampling for diffusion models in around 5 steps.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
[6] Zou, Chang, et al. “Accelerating diffusion transformers with token-wise feature caching.” arXiv preprint arXiv:2410.05317 (2024).
[7] Zou, Chang, et al. “Accelerating diffusion transformers with dual feature caching.” arXiv preprint arXiv:2412.18911 (2024).